
本地化部署AI实施方法及测试
起因:今日上午九点半是谷歌中国开发者大会,我观看了直播并注册了谷歌开发者身份,一般而言每次公布新模型我并不会感到惊讶,正如这次Google Gemini,令我比较意外的还是这次更新的模型仅仅只有2GB,这么低廉的成本引发了我的好奇心,借着这股劲,我部署了本地AI(Google Gemini 2GB模型还在开发中,尚未公布所以部署了其他模型)
配置(个人配置,仅供参考):电 脑:联想拯救者Y7000P处理器:AMD Ryzen 9 8945HX with Radeon Graphics 2.50 GH显 卡:NIVDIA RTX 5060内 存:16GBChatGPT oss-20B
两类模型介绍
由于OpenAI公司开源了两大AI,所以这次我们将使用其中的小模型进行部署
Click this你将会看到以下界面
这里我们可以根据自身电脑配置需求进行选择,这里的20B模型刚刚好可以满足我的电脑配置,所以这里我们将以20B模型进行演示,当然如果进不去OpenAI网页,下面我将提供两个模型对应的Hugging Face存储库
ChatGPT oss-20B ChatGPT oss-120B
什么是Hugging Face?
Hugging Face是通用的AI源代码存储地,在这里你可以找到绝大多是开源AI
下面是官方对于两类模型的简单介绍
gpt-oss-20b适用于较低延迟和本地或特殊用例(210 亿个参数,其中 36 亿个活动参数)
gpt-oss-120b适用于生产、通用、高推理用例,适合单个 80GB GPU(如 NVIDIA H100 或 AMD MI300X)(117B 参数,其中 5.1B 活动参数)
这里我们选择LM studio作为载体来运行我们的AI,下面我将介绍LM studio的安装方法以及简单的配置下载
LM studio & 模型下载
你可以进入LM studio官网,你将会看到一下页面
 这里直接下载即可,下载完成后,打开LM studio界面将如下所示
这里直接下载即可,下载完成后,打开LM studio界面将如下所示
 打开后,请复制以下代码再回到LM studio(选择合适自己的进行复制)
打开后,请复制以下代码再回到LM studio(选择合适自己的进行复制)
# gpt-oss-20blms get openai/gpt-oss-20b# gpt-oss 120blms get openai/gpt-oss-120b复制完成后应该会自动识别剪切板进行询问下载,如若没有显示,请打开左侧栏的发现,进去后搜索gpt-oss-20b(120b)直接下载即可,如下图
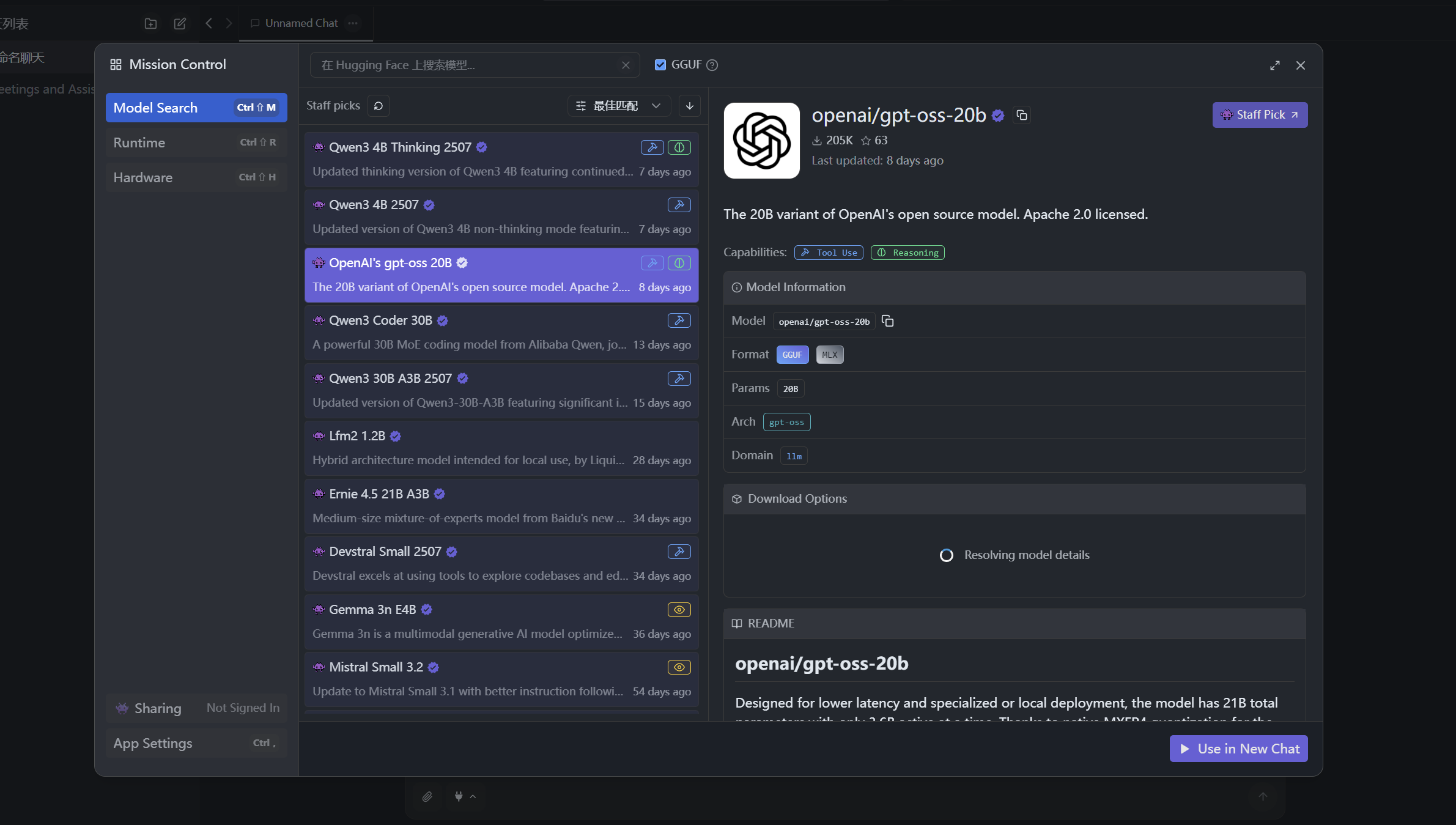 等待全部下载完成后,加载我们的模型就可以直接使用啦!
等待全部下载完成后,加载我们的模型就可以直接使用啦!
LM studio 汉化
在右下角的设置点击进去即可找到语言选择,选择自己喜好的语言即可
stable-diffusion-v1-4
介绍
这个模型是一个图片生成的模型(这个模型比较小,别指望生成精致的图片,图一乐即可哈哈哈哈哈) 同样的可以在Hugging Face找到此模型 stable-diffusion-v1-4
安装必备库
由于模型的特殊性,这里我们需要借助Python进行安装和使用,本模型依赖Pytorch插件,所以请先下载相关库
pip install --upgrade diffusers transformers scipypip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118- diffusers:Hugging Face 提供的开源库,用来加载和运行扩散模型(Stable Diffusion 就是扩散模型)。
- transformers:管理模型结构和相关任务的通用库。
- scipy:科学计算库,扩散模型运行时可能用到。
全部安装完成后,请在终端输入以下代码来检查显卡加速是否生效
python -c "import torch; print(torch.cuda.is_available())"若返回True即生效
首次使用操作方法
请一定要看完全部再按照以下文档再自己选择合适的方法操作 请在代码编辑器中新建py文档进行首次下载和测试
import torchfrom diffusers import StableDiffusionPipeline
def main(): model_id = "CompVis/stable-diffusion-v1-4" device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型,float16 省显存(显卡显存低于4GB一定要用) pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe = pipe.to(device)
# 如果显存有限,启用切片减少占用 pipe.enable_attention_slicing()
prompt = "a photo of an astronaut riding a horse on mars" print(f"Generating image for prompt: {prompt}")
image = pipe(prompt).images[0]
# 保存生成的图片 image.save("astronaut_rides_horse.png") print("Image saved as astronaut_rides_horse.png")
if __name__ == "__main__": main()当然这里默认模型安装路径就是和python安装路径是一样的,如果你的python和我的一样是在C盘内,那么我们可以通过更改一下步骤进行换到其他盘里面去 例如,我想把模型下载到D盘里面的Models文件夹,那么我们可以对刚刚的代码进行以下更改
import osimport torchfrom diffusers import StableDiffusionPipeline
# 先设置环境变量(可选)os.environ["HF_HOME"] = "D:/models" # 可以更改到自己想到的地方os.environ["TRANSFORMERS_CACHE"] = "D:/models" # 路径同上
def main(): device = "cuda" if torch.cuda.is_available() else "cpu" pipe = StableDiffusionPipeline.from_pretrained( "CompVis/stable-diffusion-v1-4", cache_dir="D:/models", torch_dtype=torch.float16 ) pipe = pipe.to(device) pipe.enable_attention_slicing()
prompt = "a photo of an astronaut riding a horse on mars" image = pipe(prompt).images[0] image.save("astronaut_rides_horse.png") print("Image saved.")
if __name__ == "__main__": main()当然这里又出现了一个疑问,我们的生成的图像保存在哪里呢? 注意这里
image.save("astronaut_rides_horse.png")如果我们想要保存在桌面,我们可以进行如下修改
image.save("XXX/Desktop/astronaut_rides_horse.png")这里的astronaut_rides_horse.png名称可以自定义
初次运行会进行模型下载工作,这里我们只需要等待即可(需要梯子)
等到Image saved出现,那么恭喜你,首次使用大获成功
后续使用的操作
如果说我们再次运行上面的程序,那么就会造成二次下载,所以现在我们需要编写一个新程序进行后续长期的使用 下面我将提供一套标准模板进行调用模型和使用(支持单次/多次使用)
import osimport torchfrom diffusers import StableDiffusionPipeline
# -----------------------------# 1. 设置模型路径和缓存目录# -----------------------------MODEL_PATH = r"D:/models/stable-diffusion-v1-4" # 本地模型目录OUTPUT_DIR = r"D:/models/output" # 输出图片保存目录
os.makedirs(OUTPUT_DIR, exist_ok=True)
# -----------------------------# 2. 初始化模型 (只做一次)# -----------------------------device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = StableDiffusionPipeline.from_pretrained( MODEL_PATH, torch_dtype=torch.float16 # 节省显存).to(device)
pipe.enable_attention_slicing() # 显存优化,尤其显卡小于8GB
# -----------------------------# 3. 定义生成图片函数# -----------------------------def generate_image(prompt, filename): """生成图片并保存""" image = pipe(prompt).images[0] save_path = os.path.join(OUTPUT_DIR, filename) image.save(save_path) print(f"Image saved: {save_path}")
# -----------------------------# 4. 批量生成示例# -----------------------------prompts = [ ("a fantasy landscape with dragons", "dragons.png"), ("a futuristic city at sunset", "city.png"), ("a cute cat wearing a spacesuit", "cat.png")]
for prompt_text, filename in prompts: generate_image(prompt_text, filename)
print("All images generated!")请根据需求,适当修改上述代码 当我们终于搞定时,去运行结果发现又报错了,这个原因是因为我们的初次下载的模型所在目录是有问题的,我们需要重新构建文件树 首次下载的文件树是
D:.├─blobs├─refs└─snapshots └─133a221b8aa7292a167afc5127cb63fb5005638b ├─feature_extractor ├─safety_checker ├─scheduler │ └─.ipynb_checkpoints ├─text_encoder ├─tokenizer ├─model_index.json ├─unet └─vae这个时候我们需要在同文件夹下(我原来下载在Models文件夹下,那么同样在Models里面新建一个stable-diffusion-v1-4文件夹,把snapshots/133a221b8aa7292a167afc5127cb63fb5005638b/下所有文件(夹)复制进去
然后把这个新文件夹的路径设置为Model Path即可使用
以下是示例生成图片
 所以说玩玩乐呵乐呵就行了
所以说玩玩乐呵乐呵就行了