
前言
本文档仅仅解释基于Yolo v8训练出来的数据集反馈效果图表进行解释
训练数据:12张图片训练,12张图片验证
项目架构
yolo/│├─ .venv/ # 虚拟环境├─ dataset/ # 数据集│ ├─ images/│ │ ├─ train/│ │ └─ val/│ └─ labels/│ ├─ train/│ └─ val/│├─ models/ # 保存训练后的模型│├─ configs/│ └─ data.yaml # 数据集配置│├─ train.py # 训练脚本├─ detect.py # 推理脚本├─ .gitignore└─ README.md解释:
在dataset文件夹中,image用于存放训练和验证图片集,labels用于存放训练和验证YOLO数据标注集
集:集合
开始训练
在终端输入以下命令即可开始训练(作用是生成模型文件.pt)
yolo detect train data=configs/data.yaml \ model=yolov8n.pt \ epochs=50 \ imgsz=640 \ batch=4 \ device=cpu \ project=models \ name=yolo_train部分解释:
batch:训练内核数量
device:训练方式(GPU/CPU)
后面会生成两个模型文件best.pt和last.pt
反馈图解释
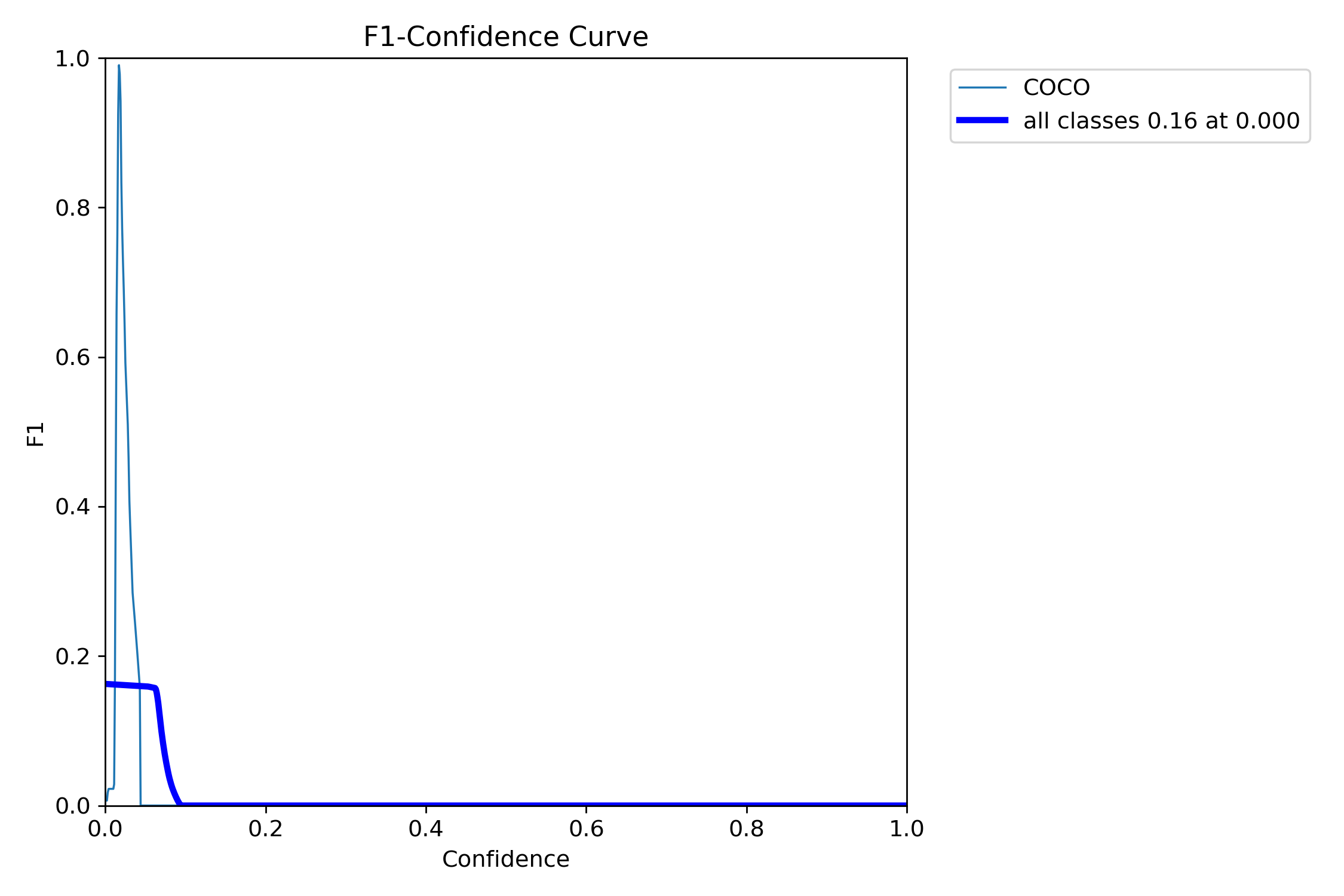
F1 Score(F1 分数)
- F1 是 精确率和召回率的折中
-
- 精度高但是漏掉很多 → F1 不高
-
- 漏检少但是误报多 → F1 不高
- 图上通常有一个峰值,告诉你置信度选择多少时 精度和召回率最平衡
解读图表:
F1 值整体偏低,说明模型在召回率和精确率之间的平衡不佳。在极低置信度下才能勉强获得一点 F1 值,一旦提高阈值,模型就几乎没有有效预测
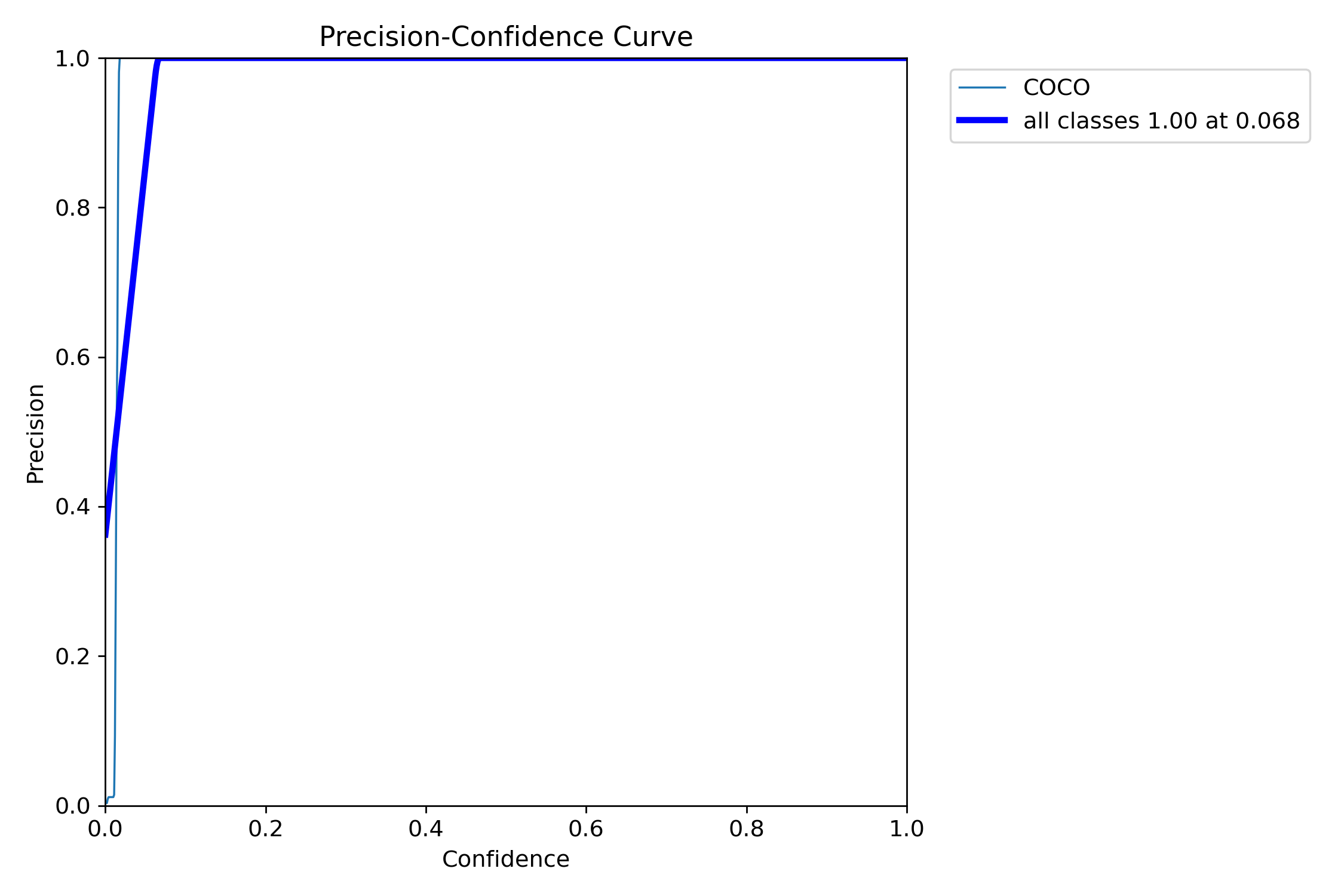
Precision(精确率)
- 精确率 = “我说这是目标的东西,有多少是真的目标?”
- 图上是 精度随置信度变化的曲线
置信度越高(模型越确信这是目标),精度一般越高,但可能会漏掉一些真实目标
解读图表:
当置信度阈值设得足够高时,模型预测的结果都是完全准确的(没有误报)。但这也意味着,为了保证精确率,模型牺牲了大量的召回率
Recall(召回率)
- 召回率 = “所有真实目标,我找到了多少?”
- 图上也是随置信度变化
置信度太高会漏掉真实目标 → 召回率下降
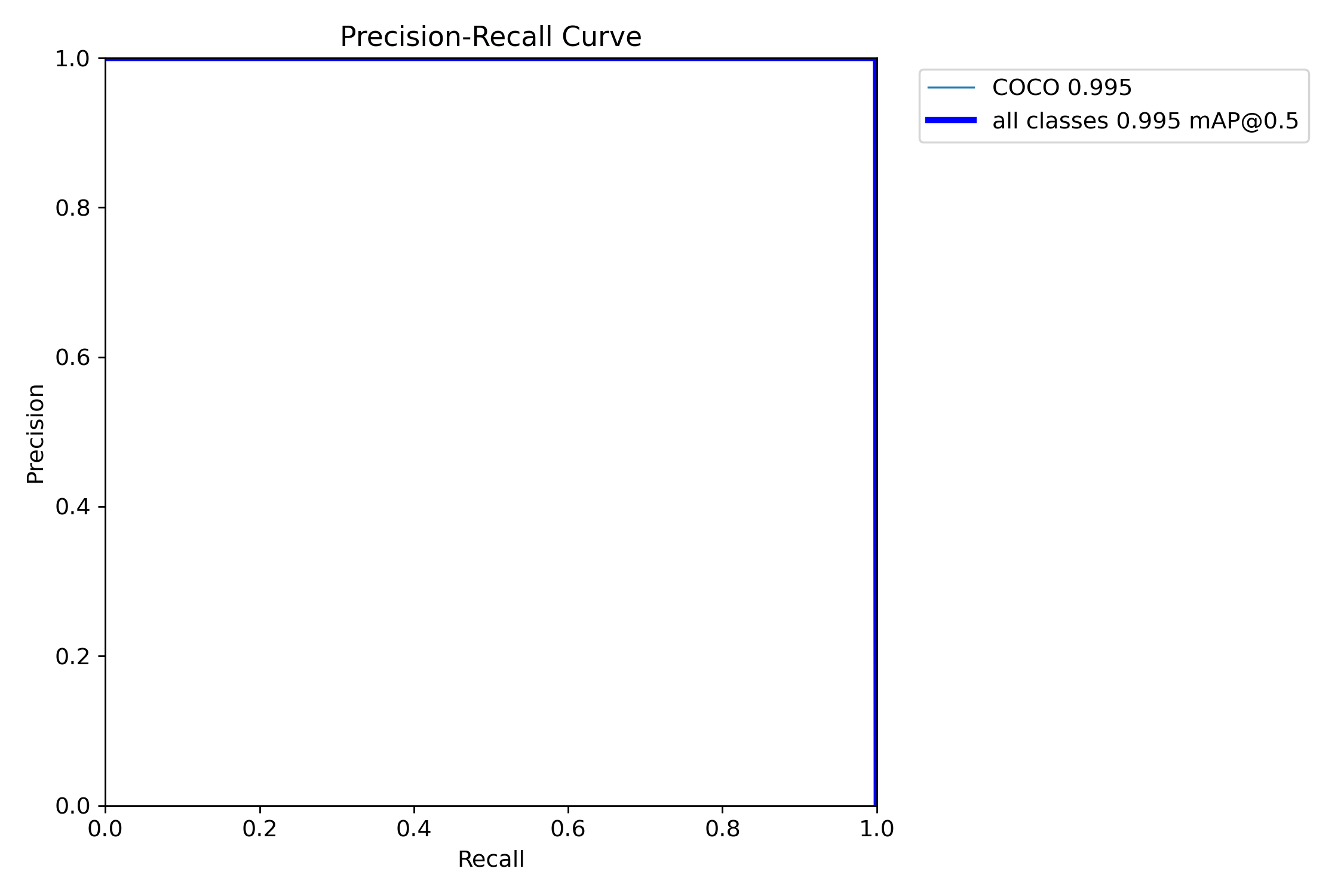
PR Curve(Precision-Recall 曲线)
- 横轴:召回率
- 纵轴:精确率
- 曲线越靠右上角,模型性能越好
- 看这图就知道模型是偏保守(精度高、召回低)还是偏大胆(召回高、精度低)
mAP(Mean Average Precision,平均精度)
评估目标检测模型的综合指标,考虑了精确率和召回率在不同置信度阈值下的表现
- mAP50:IoU=0.5 时的平均精度
- mAP50-95:IoU 0.5~0.95 的平均精度
- 模型预测框和真实框重叠得越好,mAP 越高
解读图表:
mAP@0.5:0.995,这是一个非常高的数值
这个指标看似完美,但结合其他曲线来看,这很可能是因为数据量极小或类别单一导致的 “假完美”。在实际应用中,这个 mAP 值的参考意义有限
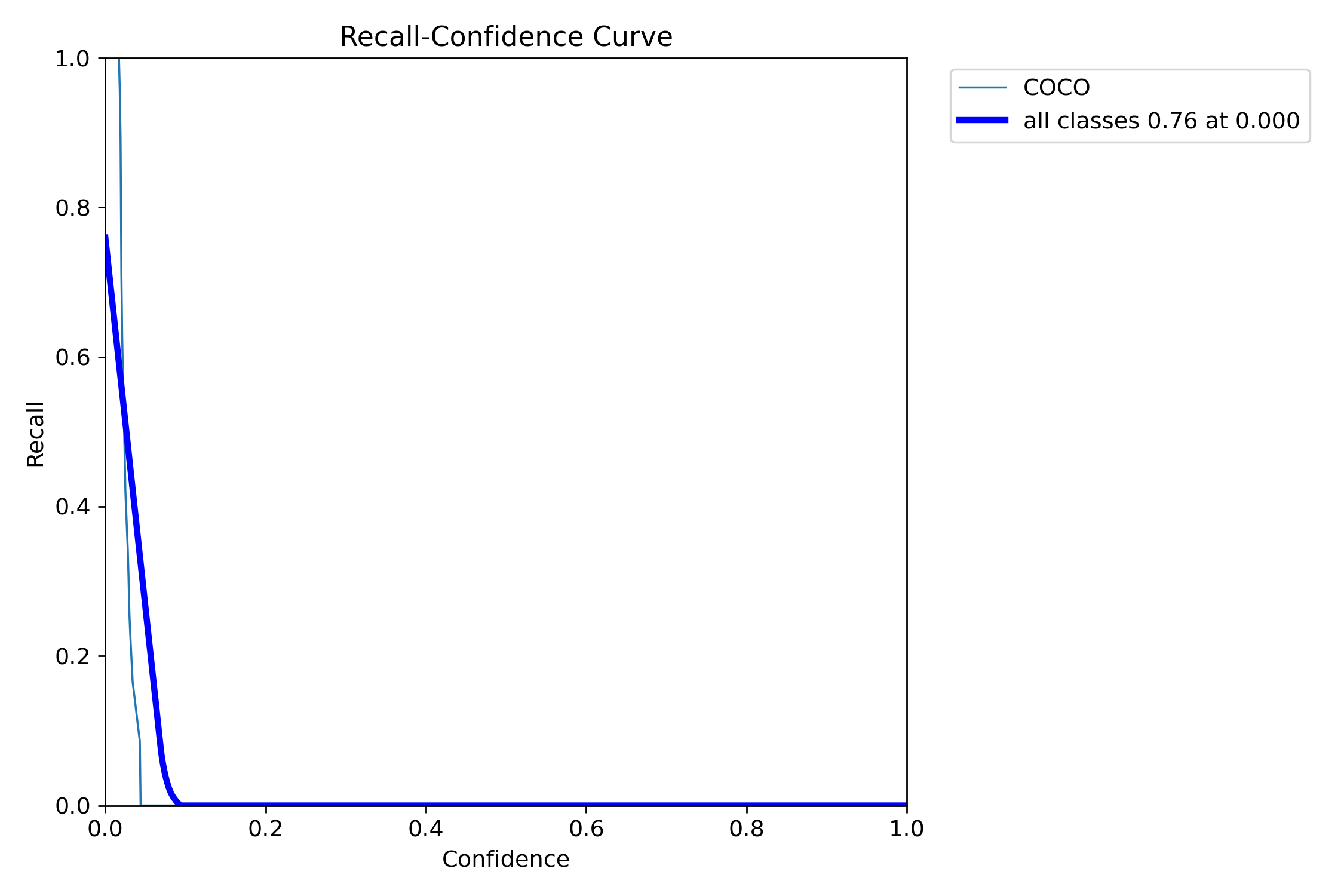
图表解读:
模型在完全不筛选(置信度为 0)时,能检测到 76% 的目标,但只要稍微提高置信度,就几乎检测不到任何目标了。这说明模型对目标的区分能力很弱,大量低置信度的预测其实是噪声
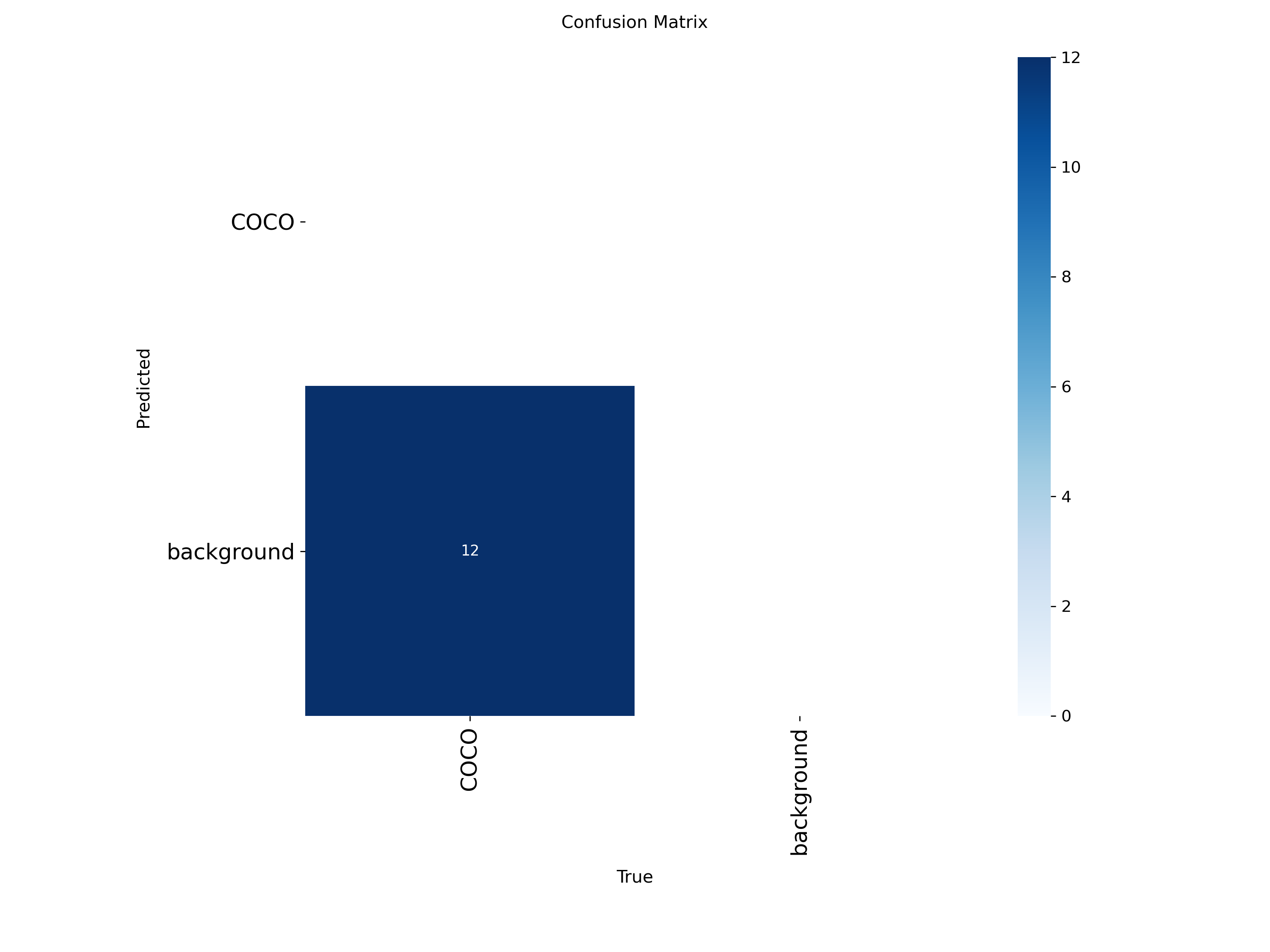
Confusion Matrix(混淆矩阵)
- 行 = 真实类别
- 列 = 模型预测类别
- 对单类任务,主要看 TP(预测对的数量)、FP(误报)、FN(漏报)
- 越多对角线越深色 → 越好,说明模型预测对的多
图表解读:
数据:所有 12 个真实的 “COCO” 样本,都被正确预测为 “COCO”。没有将背景误判为目标,也没有将目标误判为背景
解读:在这个极小的测试集(12 个样本)上,模型的分类结果是完美的。这也解释了为什么 mAP@0.5 高达 0.995
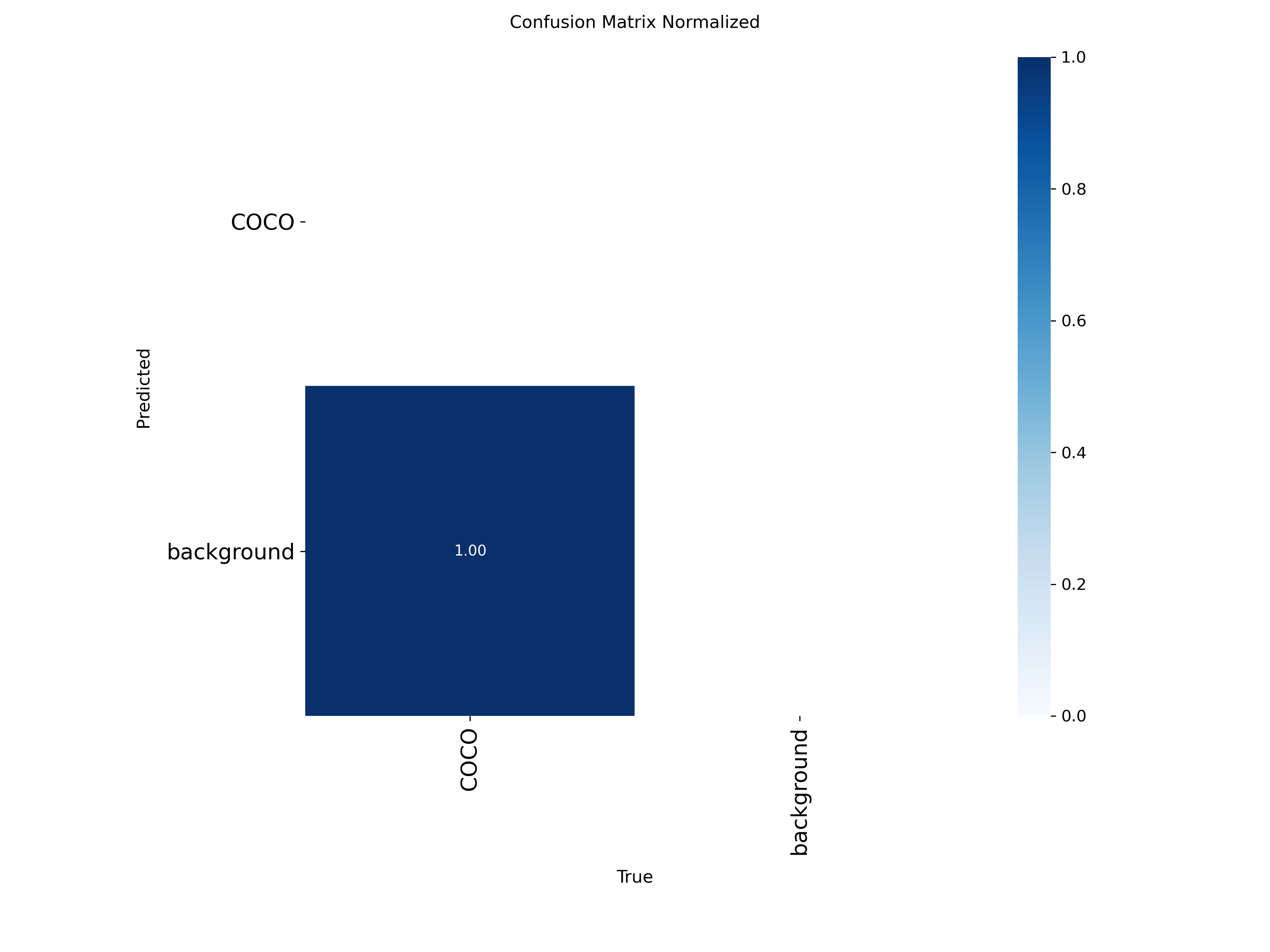
图表解读:
数据:归一化后,对角线值为 1.00
解读:进一步确认了在这个测试集上,模型的分类准确率是 100%。但这是基于极小样本量得出的结论,不具备泛化能力
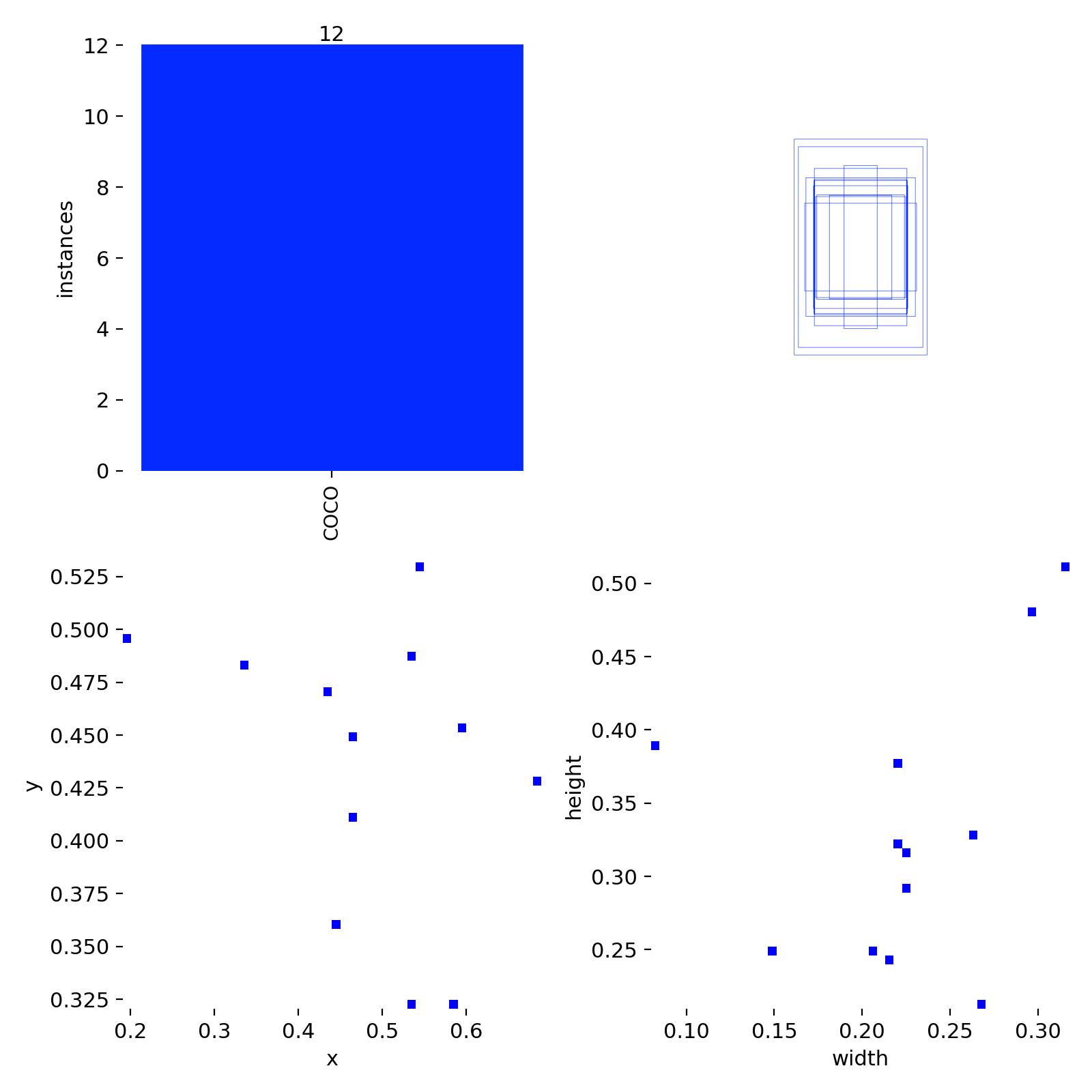
图表解读
数据集非常小且单一,这是导致评估指标 “看起来很美” 但实际泛化能力差的根本原因
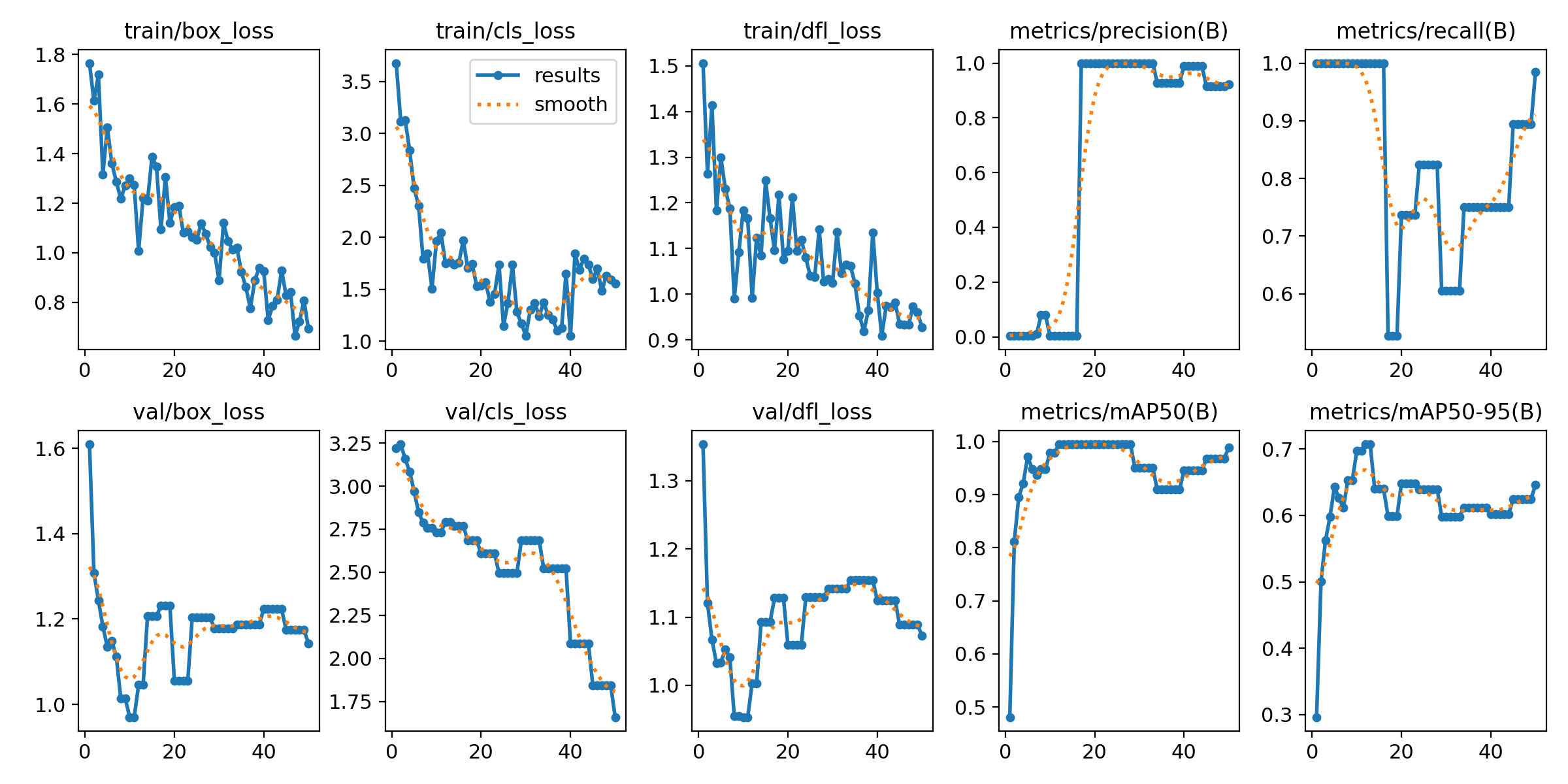
图表解读:
损失曲线
- train/box_loss, train/cls_loss, train/dfl_loss 都在稳步下降,说明模型在训练集上正在学习
- val/box_loss, val/cls_loss, val/dfl_loss 也在下降,说明模型在验证集上也在收敛,没有明显的过拟合
指标曲线- precision(B), recall(B), mAP50(B), mAP50-95(B) 都在训练初期迅速提升到很高的水平,然后趋于稳定
解读:训练过程是健康的,模型确实学到了东西。但由于数据集太小,这些指标的提升更多是对训练数据的记忆,而不是对新数据的泛化能力