
构建一个简单的AI模型入门指南
引言
由于所学知识的增加,以及对AI的好奇,我决定尝试构建一个简单的AI模型作为我AI 学习的入门项目
本文将依据网上资料,ChatGPT的帮助,以及个人经验,介绍如何构建一个基础的AI模型。具体数学原理等到后续有时间再补充。
关于AI模型
AI的本质是什么?如何去定义一个AI?
在我看来,AI的本质实际上是让机器通过数据和算法“学习”并发现规律,在此基础上进行预测或生成内容。
组成要素
- 数据(Data):原材料,训练/验证/测试集
- 模型/表示(Model/Representation):用数学或结构表示规律
- 学习算法(Learning Algorithm):如何从数据中调整模型参数(eg:梯度)
- 目标/损失(Objective/Loss):定义标准(准确率)
- 评估与泛化(Evaluation/Generalization):测试模型在新数据上的表现
- 部署与反馈(Deployment/Feedback):实际应用和持续改进(线上A/B,持续学习)
判断一个AI
- 可以从经验(数据)改善自身(具有学习能力)
- 能推断/预测新数据(不是训练数据)
- 能在某类任务上可以自动化决策
- 自适应……
分类
- ANI(Artificial Narrow Intelligence,弱AI):专注于特定任务(eg:图像识别)
- AGI(Artificial General Intelligence,强AI):具备广泛认知能力(eg:ChatGPT)
- ASI(Artificial Super Intelligence,超AI):超越人类
构建一个简单的AI模型(以二分类为例)
实现步骤(理论)
- 明确任务
- 收集或构造数据:CSV,Excel,数据库
- 特征工程:清洗数据,缺失值处理,标准化,one-hot编码
- 选择模型与训练:eg:逻辑回归,决策树,神经网络
- 评估模型:混淆矩阵,ROC,交叉验证,F1-score
- 部署或保存:保存模型,API
一些定义的解释
清洗数据:把原始数据转为适合建模的形式(去噪、统一格式、移除重复、修正错误等)
缺失值处理:均值填充,删除行/列
标准化:把特征缩放到可比的数值范围,常用于基于距离或梯度的模型
one-hot编码:把类别特征转换为二进制向量,每个类别对应一列(互斥)
混淆矩阵:二分类或多分类预测结果的计数表(TP/FP/FN/TN)
ROC曲线:ROC 曲线以假阳性率(FPR)为横轴、真正率(TPR)为纵轴
交叉验证:把训练集分成多个折(folds),轮流作为验证集以评估模型稳定性
F1-score:精确率(Precision)和召回率(Recall)的调和平均:F1 = 2 * (P * R) / (P + R)
用scikit-learn写一个简单的二分类AI模型
环境准备
建议环境Python 3.8+
- 建立一个虚拟环境(可选)
# windows [powershell]python -m venv venv.\venv\Scripts\Activate.ps1
# macOS/Linuxpython3 -m venv venvsource venv/bin/activate- 安装依赖
pip install numpy pandas scikit-learn joblib flask- joblib: 保存/加载模型
- flask: 做成HTTP任务
训练脚本
将下列代码保存为train_model.py
# ==============================================================# Author: Frees Ling# Created: 2025-10-24# Description: A script to train a simple logistic regression model# to predict student pass/fail based on hours studied.# Version: 1.0# ==============================================================import argparseimport pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, classification_report, confusion_matriximport joblibimport os
from tensorflow.python.data.util.structure import NoneTensor
def load_data(csv_path): """ CSV format: hours_studied, passed passed: 0 or 1 """ df = pd.read_csv(csv_path) # check assert 'hours_studied' in df.columns and 'passed' in df.columns, "CSV must have hours_studied and passed columns" X = df[['hours_studied']].values Y = df['passed'].values return X, Y
def train_save(csv_path, model_out='model.joblib', scaler_out='scaler.joblib', test_size=0.2, random_state=42): X, Y = load_data(csv_path) X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=test_size, random_state=random_state, stratify=Y if len(np.unique(Y)) > 1 else None)
scaler = StandardScaler() X_train_s = scaler.fit_transform(X_train) X_test_s = scaler.transform(X_test)
model = LogisticRegression(max_iter=200) model.fit(X_train_s, Y_train)
Y_pred = model.predict(X_test_s) print("Accuracy:", accuracy_score(Y_test, Y_pred)) print("Confusion Matrix:\n", confusion_matrix(Y_test, Y_pred)) print("Classification Report:\n", classification_report(Y_test, Y_pred))
joblib.dump(model, model_out) joblib.dump(scaler, scaler_out) print(f"Saved model -> {model_out}, scaler -> {scaler_out}")
if __name__ == "__main__": parser = argparse.ArgumentParser(description='Simple AI First test') parser.add_argument('--csv', type=str, default="data.csv", help='Path to the CSV data file') parser.add_argument('--model_out', type=str, default="model.joblib", help='Path to save the trained model') parser.add_argument('--scaler_out', type=str, default="scaler.joblib", help='Path to save the scaler') parser.add_argument('--test_size', type=float, default=0.2, help='Test size') parser.add_argument('--random_state', type=int, default=42, help='Random state for reproducibility') args = parser.parse_args()
if not os.path.exists(args.csv): #If no csv file, create a sample one sample = pd.DataFrame({ 'hours_studied': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'passed': [0, 0, 0, 0, 1, 1, 1, 1, 1, 1] }) sample.to_csv(args.csv, index=False) print(f"Sample data created at {args.csv}. Edit it to add your data, then re-run training.") train_save(args.csv, args.model_out, args.scaler_out, args.test_size, args.random_state)运行训练脚本
- 使用示例数据自动生成并训练
python train_model.py# 注意要在同一文件夹下运行- 或者使用自己的CSV数据
python train_model.py --csv your_data.csv --model_out my_model.joblib --scaler_out my_scaler.joblib注意:
- CSV必须有
hours_studied和passed两列(你可以拓展特证名,然后在load_data修改)- 在里面我是用
stratify = Y来保证训练集和测试集的类别分布一致
运行示例图如下
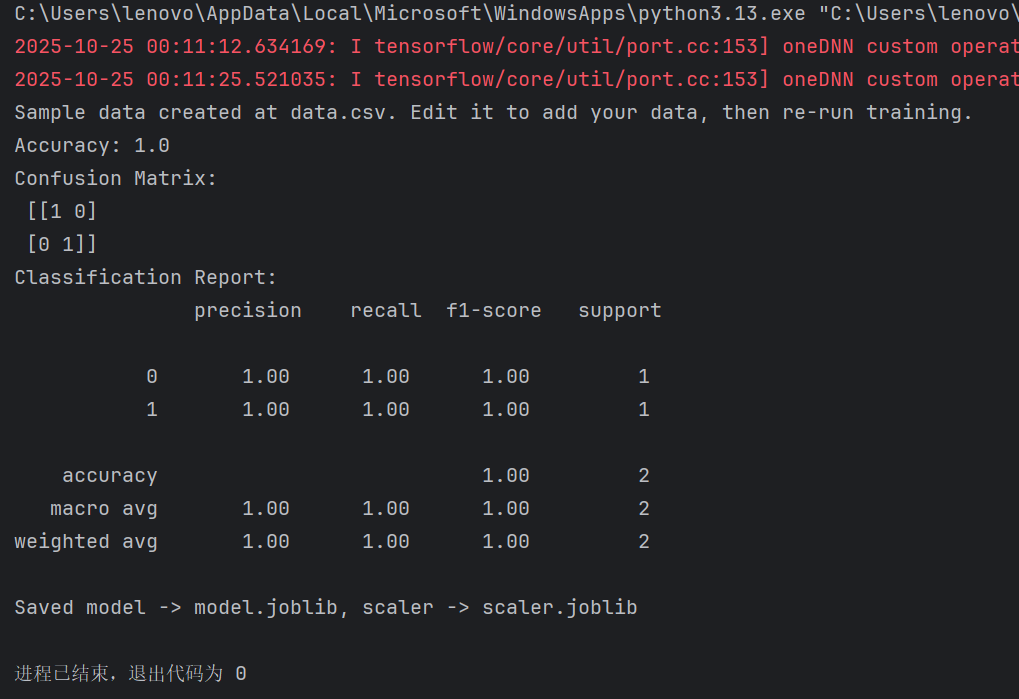 如果没有csv文件,会自动生成一个示例文件
如果没有csv文件,会自动生成一个示例文件data.csv,你可以编辑它来添加自己的数据,然后重新运行训练脚本。
加载模型并进行预测(命令行)
将下列代码保存为predict_cli.py
# ==============================================================# File: predict_cli# Author: Frees Ling# Created: 2025/10/24# Description: Cli tool to predict student pass/fail using a trained model# Version: 1.0# ==============================================================import argparseimport joblibimport numpy as np
def predict(hours, model_path='model.joblib', scaler_path='scaler.joblib'): model = joblib.load(model_path) scaler = joblib.load(scaler_path) X = np.array(hours).reshape(-1,1) X_s = scaler.transform(X) preds = model.predict(X_s) probs = model.predict_proba(X_s)[:,1] return preds, probs
if __name__ == "__main__": parser = argparse.ArgumentParser(description='Predict student pass/fail based on hours studied') parser.add_argument('--hours', type=float, nargs='+', help='List of hours studied') parser.add_argument('--model_path', type=str, default='model.joblib', help='Path to the trained model') parser.add_argument('--scaler_path', type=str, default='scaler.joblib', help='Path to the scaler') args = parser.parse_args() preds, probs = predict(args.hours, args.model_path, args.scaler_path) for h, p, prob in zip(args.hours, preds, probs): print(f"Hours Studied: {h} => predict={int(p)}, prob_of_pass={prob:.3f}")运行实例:
python predict_cli.py --hours 2 4 6 8 10# 输出示例# Hours Studied: 2.0 => predict=0, prob_of_pass=0.123# Hours Studied: 4.0 => predict=0, prob_of_pass=0.345# Hours Studied: 6.0 => predict=1, prob_of_pass=0.678# Hours Studied: 8.0 => predict=1, prob_of_pass=0.890# Hours Studied: 10.0 => predict=1, prob_of_pass=0.950
把模型做成HTTP服务(Flask)
将下列代码保存为app.py
# ==============================================================# File: model_html# Author: Frees Ling# Created: 2025/10/24# Description: curl command to get model summary in HTML format# Version: 1.0# ==============================================================# app.pyfrom flask import Flask, request, jsonifyimport joblibimport numpy as np
app = Flask(__name__)MODEL_PATH = "model.joblib"SCALER_PATH = "scaler.joblib"
model = joblib.load(MODEL_PATH)scaler = joblib.load(SCALER_PATH)
@app.route("/predict", methods=["POST"])def predict(): """ receipt JSON: {"hours":[2.2 4.5 6.0]} return : [{"hours":2.2,"predict":0,"prob":0.123},...] """ data = request.get_json() if not data or 'hours' not in data: return jsonify({"error": "please send JSON with 'hours' list"}), 400 hours = np.array(data['hours']).reshape(-1, 1) Xs = scaler.transform(hours) preds = model.predict(Xs) probs = model.predict_proba(Xs)[:, 1] out = [] for h, p, prob in zip(hours, preds, probs): out.append({"hours": float(h[0]), "predict": int(p), "prob": float(prob)}) return jsonify(out)
if __name__ == "__main__": app.run(host="0.0.0.0", port=8080, debug=True)运行Flask服务:
python app.py测试(要另开一个终端)
Invoke-WebRequest -Uri "http://127.0.0.1:8080/predict" ` -Method POST ` -Body '{"hours":[2.2,4.63,255]}' ` -ContentType "application/json"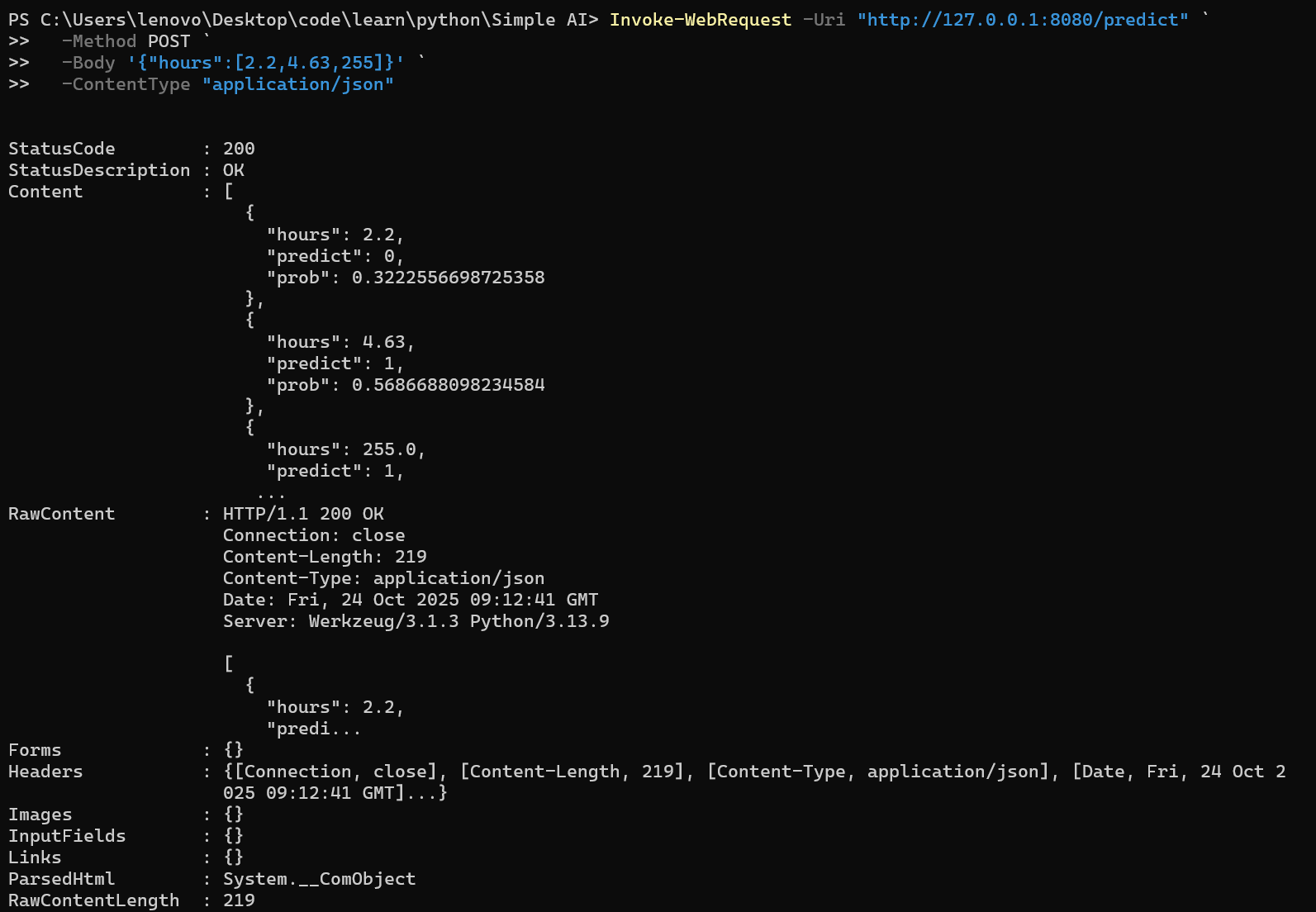
这里我让我的朋友在远程测试了一下这个API服务,以下是他发回来的截图
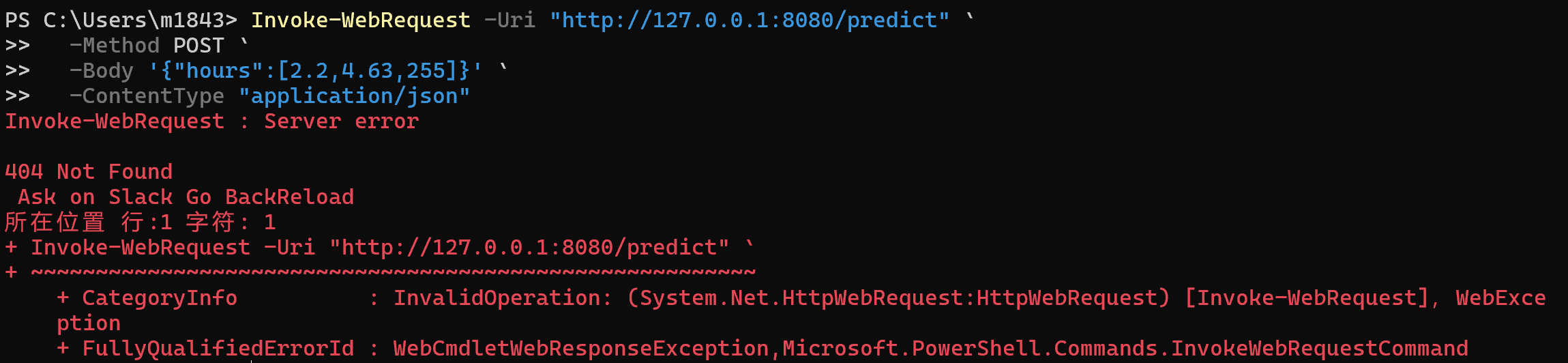 换一个IP地址试试呢
换一个IP地址试试呢
 这就很有意思了,为什么远程无法调用呢?
这就很有意思了,为什么远程无法调用呢?
经过一番排查,发现是因为防火墙的问题,默认情况下,Flask只允许本地访问,无法接入公网,所以远程无法访问。
当然也不是不无解决方法,我们可以通过以下几种方式解决这个问题:
- 关闭防火墙(不推荐,安全风险)
- 配置防火墙规则,允许8080端口的入站流量
- 使用反向代理(如Nginx)将请求转发到Flask应用
- 使用云服务(如Heroku, AWS)部署Flask应用
- 使用ngrok等工具创建公网隧道
后记:AI学习之路任重而道远,本文只是一个入门级别的尝试,希望能帮助到和我一样的AI初学者。未来我会继续深入学习AI相关知识,并分享更多有趣的项目和经验。感谢阅读!